

Mis à jour le
3/10/2025
Apprenez à faire du web scraping avec Python grâce à notre article expert.
.jpeg)
La matière première du Data Analyst, c’est la donnée.
Or en 2022, une grande partie de cette donnée est disponible sur Internet : tout l’enjeu est de la récupérer !
Le web scraping est la technique qui permet au Data Analyst d’extraire directement depuis le Web les informations sur lesquelles il veut travailler.
Imaginez pouvoir automatiser la collecte d'informations sur vos sites web préférés, les mettre en forme pour les analyser, et tout cela sans avoir à faire de copier-coller fastidieux.
Bienvenue dans le monde vibrant du Web Scraping avec Python !
Que vous soyez un développeur chevronné ou un novice curieux, cette technique est un passeport pour le Data Mining.
Le web scraping, c’est un peu comme envoyer un robot dans une librairie pour qu’il vous rapporte des livres spécifiques. Sauf que la librairie est un site web et les livres sont des données.
En utilisant Python, un langage clair comme de l'eau de roche, vous pouvez écrire des scripts qui récupèrent des données spécifiques à partir de pages web automatiquement.
Python est souvent loué pour sa facilité d'utilisation et son code lisible, ce qui le rend parfait pour le web scraping, c'est-à-dire l'extraction de données à partir de sites web.
Lorsqu'on parle de la "bibliothèque riche" de Python, on fait référence à l'ensemble des modules et des outils pré-fabriqués qui sont disponibles pour simplifier le développement de certaines tâches.
En matière de web scraping, deux outils Python sont particulièrement populaires :
- Beautiful Soup : C'est une bibliothèque qui permet de parser des documents HTML et XML. Elle crée des parse trees qui sont utiles pour extraire les données de façon facile et intuitive.
Si on poursuit la métaphore de la pêche, Beautiful Soup serait comme un filet qui peut être lancé dans l'océan des pages web pour capturer les informations désirées.
- Scrapy : C'est un framework plus avancé utilisé pour le web crawling (exploration automatique du web) et l'extraction de données.
Imagine que tu veuilles déterminer le prix moyen des romans vendus sur le site de la Fnac. Tu dois pour cela récupérer le prix de chaque référence à la vente. Tu peux essayer de les recopier à la main dans un fichier Excel, ou bien de les copier-coller si tu veux gagner un peu de temps. Mais te sens-tu prêt à parcourir les centaines de pages du site de la Fnac ?
Si la réponse est non, alors le web-scraping est la solution qu’il te faut.
De l’anglais “to scrape”, web-scraping signifie littéralement “grattage de web” (et il est d’ailleurs appelé ainsi par certains). Il s’agit d’une méthode pour automatiser la récupération de données sur le Web, qui peut être mise en œuvre grâce à Python.
Le web-scraping permet de collecter des données :
Ce dernier point est crucial pour le Data Analyst, qui a besoin d’un grand nombre de données pour entraîner les algorithmes de modélisation avec lesquels il travaille.
Le scraping se décompose en deux étapes :
Ces deux étapes permettent de constituer une base de données exploitable.
Dans un premier temps, le Data Analyst utilise Python pour télécharger le code HTML de la page Internet qui l’intéresse. Qu’est-ce que le code HTML ?
C’est l’envers du décors de la page Internet, c’est-à-dire une série d’instructions et de balises qui contiennent les informations qui s’affichent sur l’écran de l’utilisateur : le texte, les titres, les liens hypertextes etc…

Remarque : le code HTML travaille “en binôme” avec le code CSS. Ce dernier s’occupe du design : la taille des éléments, leur couleur etc…
Par curiosité, tu peux tout de suite accéder au code HTML de la page Web sur laquelle tu lis cet article. ll te suffit de faire un clique-droit sur un élément puis de sélectionner “Inspecter” (sur navigateur Chrome ou Firefox, par exemple). Tu vois alors une petite fenêtre s’ouvrir : elle contient le code HTML de la page, et plus précisément celui de l’élément sur lequel tu as cliqué.
En récupérant le code HTML d’une page web, le Data analyst télécharge toutes les informations qu’elle contient.
La deuxième étape est celle du parsing. Concrètement, il s’agit de lire le code HTML afin de repérer où se trouvent les informations que tu souhaites collecter.
Remarque : il existe des fonctions Python qui rendent le code HTML plus propre, par exemple en ajoutant des sauts de ligne à certains endroits. C’est très pratique quand on a pas l’habitude de lire du code.
Dans le code HTML d’une page web, les informations sont associées à différents types de balises :
Il existe des dizaines de balises différentes qui répondent à un besoin spécifique. Pour scraper une page web, il faut tout d’abord repérer la ou les balises associées aux informations que tu souhaites récolter. Ensuite, une fonction Python permet d’extraire ces informations à partir du code HTML.
Il peut s’agir par exemple de tous les prix sur une marketplace, ou de tous les titres de paragraphes sur un article Wikipédia…
Une fois que les données intéressantes ont été collectées, elles sont placées dans des listes ou des dictionnaires Python. A partir de là, il est tout à fait possible de constituer une base de données parfaitement exploitable.
Enfin, il ne reste plus qu’à analyser ces données en utilisant par exemple les fonctionnalités de data visualisation de Python. Une partie de la formation de Databird est consacrée au web-scraping. En suivant les bons conseils de nos professeurs, un peu d’entrainement suffit à devenir un maestro de la discipline !
{{formation-python="/brouillon"}}
Le web-scraping est une technique qui a de multiples applications business. Elle est utile dans la plupart des secteurs d’activités, si ce n’est tous. En récupérant des informations, l’entreprise comprend mieux son environnement : le comportement de ses concurrents, de ses clients, les évolutions de marché, etc.

Le web-scraping permet aux entreprises d’étudier les prix de leurs concurrents afin d’adapter leur offre. Les données récoltées peuvent être insérées dans un tableau de bord afin d'aider l'équipe dirigeante à définir un prix ou les mécanismes d’une offre promotionnelle.
Un exemple : Courir, le retailer de chaussures, peut surveiller les prix pratiqués par son concurrent direct FootLocker en examinant les prix fixés pour les mêmes modèles.
Le web scraping permet de récolter des données concernant un marché spécifique et de les présenter en utilisant des techniques de dataviz. Les grands volumes de données récupérées permettent de comprendre en profondeur ce marché.
Exemple : un fabricant peut analyser le nombre de commentaires des acheteurs sur une marketplace (comme Amazon) à propos des produits similaires aux siens. En analysant leur avis, il peut ensuite adapter son offre à la popularité de certains produits.
Une entreprise peut tirer profit du Machine Learning pour améliorer son offre et ses pratiques. Or pour être efficace et fiable, un algorithme de Machine Learning doit se former à partir d’un grand volume de données.
C’est là le principal intérêt du web-scraping. Il permet de récupérer en un temps record une quantité de données appropriée pour “nourrir” les algorithmes de Machine Learning que l’entreprise veut mettre en place.
Le web-scraping permet de récupérer des informations quantitatives, mais aussi qualitatives. Il s’agit par exemple des commentaires des clients à l’égard de l’entreprise. Comme vu précédemment, le web-scraping peut être implémenté sur le site de l’entreprise, mais aussi sur les sites de ses retailers, et même sur les réseaux sociaux de la marque. On peut ainsi compiler les avis exprimés par les usagers.
Ces commentaires sont une source d’informations cruciales. Ils sont analysés avec Python grâce au NLP (Natural Language Processing). Les informations obtenues permettent d’améliorer la relation clients en comprenant leurs attentes.
Le web-scraping permet de récupérer les contacts (adresse e-mail ou numéro de téléphone) de personnes qui ont diffusé ces informations sur des sites. Une entreprise peut donc récolter les contacts de potentiels clients afin de constituer un fichier de prospection.
Si tu es en recherche d’emploi, le web-scraping est une très bonne raison d’apprendre le langage Python : cette compétence séduit tous les recruteurs.
{{formation-python="/brouillon"}}
Si tu souhaites scraper un site Internet mais que tu ne sais pas coder, c’est possible.
Tu peux utiliser les outils suivants :
Une API (Application Programming Interface) est une interface qui rend possible l’échange d’informations entre deux logiciels ou deux sites Internet. Tu peux ainsi collecter des données sans avoir à scraper le site avec Python.
Même s’il est possible d’écrire une API avec Python, de nombreux sites mettent à disposition des API REST, facilement utilisables par un développeur ou un Data Analyst. Ces API simplifient la récupération d’informations :
Il est aussi possible de scraper un site à l’aide d’un logiciel voire simplement d’une extension de navigateur. Ici encore, savoir coder n’est pas nécessaire tant que tu comprends comment le logiciel fonctionne.
Les extensions de navigateur présentent l’avantage de ne pas alourdir ton disque dur car tu les télécharges sur ton navigateur (qui peut par contre devenir plus lent si tu en abuses !).
Pour utiliser une extension de web-scraping, il suffit de se rendre sur le site que tu veux scraper et de cliquer sur l’extension qui est placée dans la barre de navigation. Elles sont en général simples à utiliser, le processus de scraping est guidé par l’extension.
Les extensions de web-scraping les plus populaires sont :
Il existe également des logiciels dédiés au web-scraping. Ils sont pour la plupart payants mais très simples à utiliser, puisqu’ils utilisent la technique du “pointer-cliquer” pour récupérer les informations désignées.
Les plus populaires sont :
Pour aller plus loin dans tes projets de web-scraping, Databird te recommande d’utiliser Python. En effet, en codant toi-même ton programme de web-scraping, tu peux :
Chez Databird, nous enseignons le web-scraping grâce aux librairies Python suivantes : Requests et BeautifulSoup.
La librairie Requests permet d’effectuer la première étape du web-scraping : le téléchargement du code HTML de la page.

La librairie BeautifulSoup se charge de la deuxième étape : le nettoyage de ce code et surtout l’extraction des informations qui t’intéressent.
BeautifulSoup est une bibliothèque très appréciée des professionnels. En effet, elle offre de nombreuses fonctions (appelées méthodes) qui sont d’une remarquable simplicité d’utilisation et qui faciliteront grandement l’analyse syntaxique du code HTML.

Tu peux compléter ton analyse avec la bibliothèque Pandas, qui permet d’agencer les données dans des tableaux et de commencer les analyses data.
Il existe d’autres bibliothèques qui peuvent compléter Requests et BeautifulSoup.
La librairie Scrapy est très puissante : elle permet de gratter quasiment n’importe quel site web en déchargeant le développeur de la configuration du scraper. Scrapy permet également de “nettoyer l’information” comme BeautifulSoup. Toutefois, Scrapy est bien plus compliqué à prendre en main que BeautifoulSoup.
La librairie Pyspider est également utile, même si elle n’est pas aussi complète que Scrapy. Son principal avantage est sa rapidité : Pyspider est capable d’envoyer une multitude de requêtes en parallèle vers un site Web, alors que les autres bibliothèques doivent les envoyer les unes après les autres. Cela réduit d’autant le temps de collecte des données.
Enfin, la bibliothèque Selenium permet de contrecarrer un des principaux obstacles du web-scraping : les sites “ajaxifiés”. Quand un site est ajaxifié, c’est-à-dire qu’il repose sur la technologie AJAX, alors les informations que tu cherches ne sont pas directement inscrites dans le code HTML. Elles sont affichées par le site à la demande de l’utilisateur, via l’exécution de tâches Javascript. Selenium permet d’exécuter ces tâches et donc d’accéder à l’information, ce que Requests ne peut pas faire.
Voici un exemple de collecte de données que tu peux réaliser avec Python. Le but ici est le suivant : créer un tableau regroupant le titre et le contenu (en deux colonnes distinctes) des avis concernant les formations Databird sur Trustpilot.
Nous allons te montrer comment réaliser cette mission en trois étapes, à l’aide des bibliothèques Requests, BeautifulSoup et Pandas.
On commence par importer les bibliothèques Requests et BeautifulSoup (qui est contenue dans la bibliothèque bs4).
On passe ensuite par plusieurs étapes pour obtenir la variable soup, qui contiendra tout le code HTML de la page mise en forme de manière lisible.
D’abord, on demande à Python d’aller chercher le contenu HTML de la page, avec son url :
Attention à bien mettre l’url entre guillemets, car Python le considère comme une chaîne de caractères.
On appelle ensuite response pour voir si la demande a bien fonctionné. Ici, tu as une “response 200” ce qui signifie que cela a bien marché. En cas d’échec, tu aurais pu avoir “response 404” par exemple, que tu connais bien.
On crée ensuite la variable soup en utilisant le contenu de response (appelé “response.content”) qui correspond au code HTML de la page de Trustpilot. La variable soup contient alors le code HTML mis en forme de manière lisible grâce à BeautifulSoup.
Le second argument de la fonction ci-dessus s’appelle le parser : c’est l’outil d’analyse que BeautifulSoup va utiliser. Si tu précises d’utiliser le “html.parser”, BeautifulSoup comprend qu’elle a affaire à un code HTML.
On améliore encore un petit peu l’aspect du code HTML en utilisant la méthode prettify.
C’est à cette étape que l’outil “Inspecter” que nous avons vu plus haut va t’être utile. Pour repérer où se situe un élément de la page Web dans le code HTML, il suffit de cliquer-droit sur cet élément puis sur “Inspecter”.
Tu ouvres alors une fenêtre qui contient tout le code HTML de la page. Pour pouvoir scraper les données, il te faut comprendre l’architecture HTML de la page et identifier où se trouve l’info qui t’intéresse. Tu pourras ainsi fournir à Python “l’adresse de la balise HTML” qui contient la donnée qu’il doit extraire.
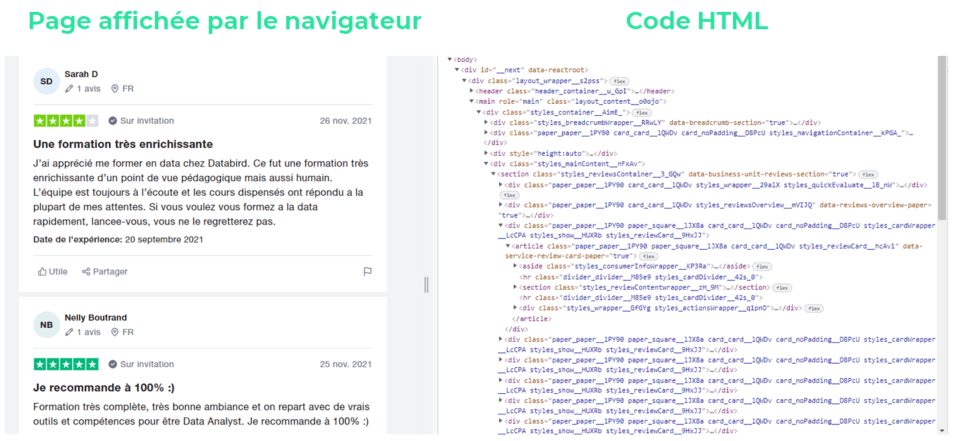
Ici, nous inspectons le titre du commentaire :“Une formation très enrichissante”. L’adresse HTML de cet élément est alors surlignée en gris dans le code HTML.

On constate qu’elle est située dans une cascade de balises : le titre du commentaire est situé dans une balise <a> qui est elle-même dans une balise <h2>.
Il faut également repérer un élément très important : toutes les informations contenues dans un avis sont encadrées par une balise <article>.
A noter : <article> est une unité de base d’une page Web. C’est un élément important du code HTML d’une page web.
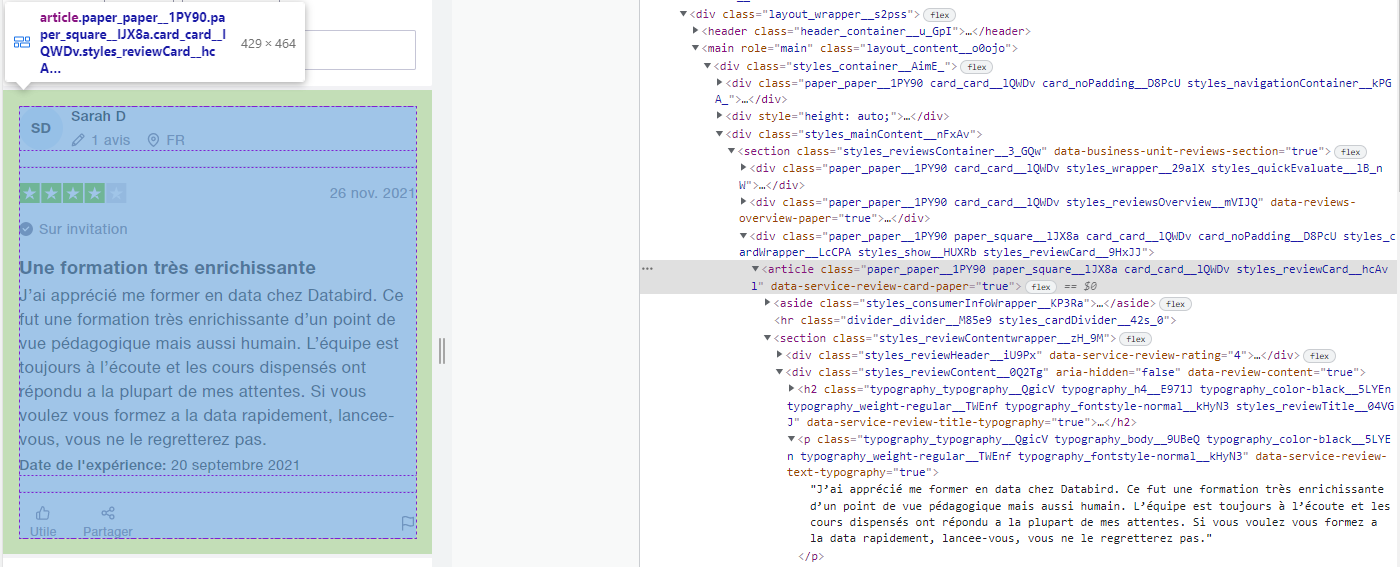
Dans cette balise <article> se trouve les deux informations qui nous intéressent : le titre du commentaire et son contenu.
Dans l’image ci-dessus, tu peux voir que <article> est associée à une class : “paper_paper__1PY90 paper_square__lJX8a card_card__lQWDv styles_reviewCard__hcAvl" .

Tu peux simplement copier-coller cette longue expression unique, elle va nous permettre d’indiquer à Python où se trouvent les informations recherchées.
Maintenant, il ne te reste plus qu’à demander à Python d’aller scraper cet avis ! Pour cela, tu peux nommer une nouvelle variable (“avis_Databird”) et utiliser la méthode soup.find() pour trouver l’information qui t’intéresse.
Ici, on dit à Python qu’on cherche une balise <article> qui a pour attribut la class qui s’appelle "paper_paper__1PY90 paper_square__lJX8a card_card__lQWDv styles_reviewCard__hcAvl". Python parcourt alors le code HTML, trouve la balise en question et stocke toutes les informations dans la variable “avis_Databird”.
Il faut maintenant isoler le titre et le contenu. Pour cela, on se souvient que le titre est contenu dans une balise <a>, elle-même contenue dans une balise <h2>. On repère aussi que le contenu est dans une balise <p>.
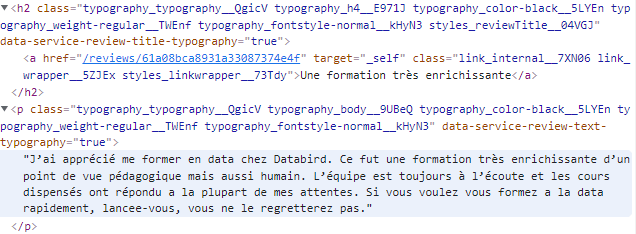
On peut alors créer les variables suivantes :
Python récupère le texte qui se situe à l’adresse indiquée. En appelant la commande “print”, tu auras en sortie :
Remarque : avec la méthode .find(), Python ne s’intéresse qu’au premier article. On va donc généraliser avec la méthode .find_all() pour obtenir une liste contenant les 20 avis affichés dans la page web !
Tu peux vérifier que tous_les_avis est bien une liste en vérifiant sa longueur avec :
Ensuite, en utilisant deux boucles for, on crée deux listes :
On utilise exactement les mêmes commandes que précédemment.
Tu as désormais deux listes très propres. Pour les agencer sous forme de tableau, il faut importer la bibliothèque Pandas.
On crée ensuite un dictionnaire qui associe chaque élément de la liste de titres avec l’élément correspondant de la liste de contenus.
Enfin, on crée une dataframe (c’est-à-dire un tableau) à partir de ce dictionnaire.
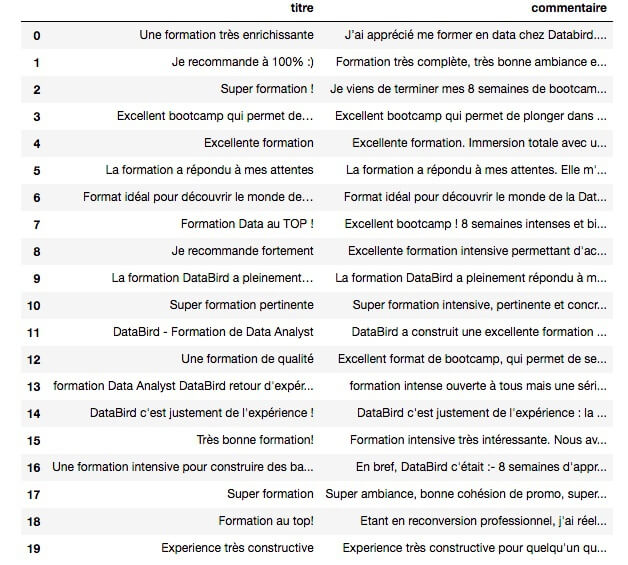
Voilà ! Tu as regroupé les titres et les contenus des commentaires en un seul tableau !
Pour récolter les avis présents sur les 3 autres pages, il te suffit d’exécuter le même code avec les URLs des pages 2, 3 et 4.
Remarque : en cours, tu apprends à automatiser le scraping de dizaines de pages web.
Tu dois certainement te demander ce que pensent les sites cibles de l’extraction de leurs données ?
La plupart l’acceptent, c’est pourquoi certains vont parfois jusqu’à mettre à disposition des API de scraping.
Dans d’autres cas, le web-scraping est un sujet sensible.
C’est pourquoi nous t’invitons à vérifier la licéité de tes projets de web-scraping avant de te lancer dedans !
Le web-scraping comporte le risque de faire planter le site cible, en raison du nombre important de requêtes qu’il génère. Il est donc déconseillé d’effectuer du scraping de données de manière trop agressive. Tu pourrais te tirer une balle dans le pied en faisant planter ton site cible.
Pour éviter ce problème, de nombreux sites mettent en place des restrictions d’accès en bannissant les robots : c’est pour ça que les internautes doivent parfois résoudre des énigmes Captcha !

Il faut également savoir que certains sites peuvent tout simplement bannir une adresse IP s'ils repèrent qu’elle génère un nombre excessif de requêtes.
Par ailleurs, le web-scraping peut s’avérer compliqué à utiliser si le site repose sur une structure AJAX, puisque le contenu de la page ne s’affiche pas directement dans le code HTML. Mais dans ce cas, la bibliothèque Selenium est ta meilleure amie !
Enfin, un algorithme de web-scraping reste efficace tant que la structure de la page Web ne change pas. Si tu souhaites scraper un site régulièrement (ça peut être utile pour effectuer une veille concurrentielle, par exemple), et que les développeurs de ce site modifient la structure HTML, il te faudra adapter ton programme de scraping.
{{formation-python="/brouillon"}}


