
.webp)
Mis à jour le
27/1/2026

À vous de choisir le format qui colle à vos ambitions :
→ Data ou IA, du niveau débutant à l'expertise métier
→ En présentiel ou à distance, à votre rythme
→ Financement CPF possible selon les formations
Découvrez comment modéliser vos données et mieux comprendre votre data pipeline dans cet article !

DBT, ou Data Build Tool, est devenu un incontournable dans la transformation de données moderne. Mais entre créer quelques modèles en SQL et bâtir une architecture de transformation scalable, automatisée et testable… il y a un monde.
Si vous avez déjà un projet DBT en production, ou si vous en êtes à vos premiers modèles et entrain de vous former à DBT, cet article vous donne les clés pour passer à la vitesse supérieure avec une modélisation avancée. On parle ici de lisibilité du pipeline, contrôle qualité, versioning, modularité – tout ce qu’un data engineer ou un analyste attend d’un bon outil open source.
Initialement, DBT permet de créer des modèles simples en SQL pour transformer les données brutes. Cependant, à mesure que les projets grandissent, cette approche peut devenir difficile à maintenir.
La modélisation avancée introduit des pratiques telles que la structuration en couches, l'utilisation de macros, les tests automatisés et la documentation, facilitant ainsi la gestion et l'évolution des pipelines de données.
Dans un projet DBT professionnel, structurer ses modèles selon une architecture en couches est une pratique incontournable.
Elle permet de clarifier le rôle de chaque transformation dans le pipeline de données, d'améliorer la lisibilité du DAG, et de rendre les projets évolutifs et maintenables sur le long terme.
Cette approche repose sur une séparation claire des responsabilités des modèles, regroupés en trois grandes catégories : Staging, Intermediate et Mart.
La couche staging est le point d'entrée de vos données brutes dans le pipeline. Ici, chaque table source est modélisée dans un fichier .sql, dans lequel vous appliquez un premier niveau de nettoyage et de standardisation.
Cela inclut notamment :
L’objectif de cette couche est de garantir une base cohérente et propre, à partir de laquelle vous allez pouvoir bâtir des transformations plus riches.
Chaque table source externe (d’un outil SaaS, d’un fichier CSV, d’un data lake, etc.) aura donc un modèle de staging dédié.
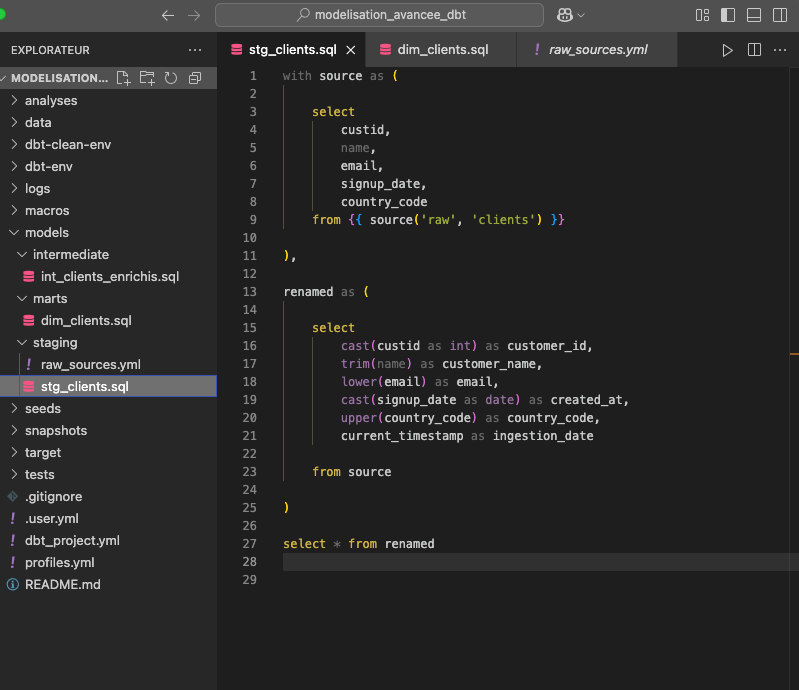
Pour notre exemple, la couche staging extrait les données brutes du CRM, les nettoie, renomme les colonnes, et ajoute un horodatage ingestion_date sans appliquer de logique métier.
Astuce : Ne mettez jamais de logique métier dans cette couche. Elle doit rester purement technique.
La couche intermediate contient les modèles qui agrègent, enrichissent ou croisent les données issues de la couche staging. C’est ici que vous appliquez la logique métier de votre entreprise : calculs de KPI, enrichissements par jointures, filtrages, transformations complexes, etc.
Ces modèles permettent de factoriser les règles métier pour éviter de les dupliquer dans les tables finales. Par exemple, si vous avez besoin de calculer la valeur d'une commande (prix × quantité - remise), faites-le dans un modèle intermediate, puis réutilisez-le dans plusieurs marts si nécessaire.
Cette couche est aussi idéale pour préparer des sous-ensembles de données spécifiques à un domaine (finance, produit, marketing) avant leur consommation finale.
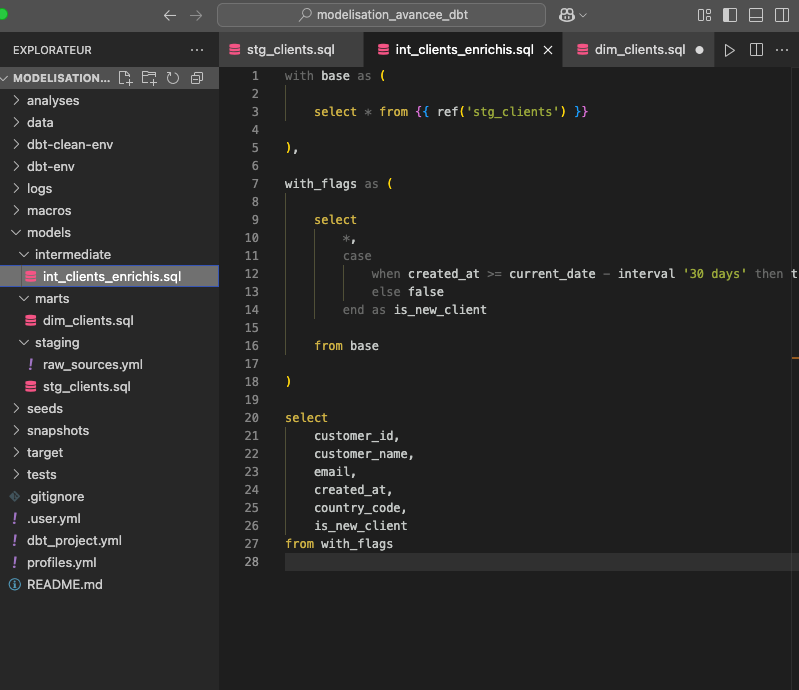
Pour notre exemple, la couche intermediate enrichit les données en identifiant les nouveaux clients grâce à une logique métier centralisée (is_new_client).
La couche mart (aussi appelée presentation layer) correspond aux modèles finaux, directement consommés par les analystes, les outils de BI ou exposés à d’autres systèmes.
On y retrouve notamment :
Ces modèles sont pensés pour la lecture et l'analyse. Ils doivent être performants, bien documentés, et aussi stables que possible, car ils sont souvent connectés à des dashboards ou des applications métier.
À ce stade, il ne doit plus rester de logique métier complexe : tout doit venir des couches précédentes.
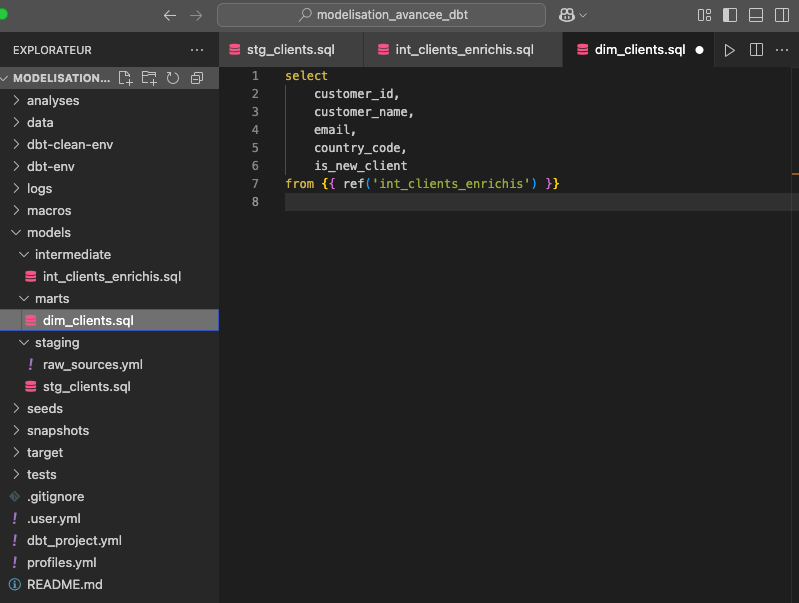
Pour notre exemple, la couche mart expose une table de dimension prête à être analysée dans un outil BI, sans contenir de transformation.
Dans dbt docs, le graphe (ou DAG – Directed Acyclic Graph) montre comment les modèles sont connectés entre eux, de la source de données brute jusqu'aux tables finales destinées à l’analyse.
Chaque nœud (boîte) représente un modèle SQL DBT. Chaque flèche indique une dépendance logique entre deux modèles : le modèle en bout de flèche utilise le modèle précédent via ref().
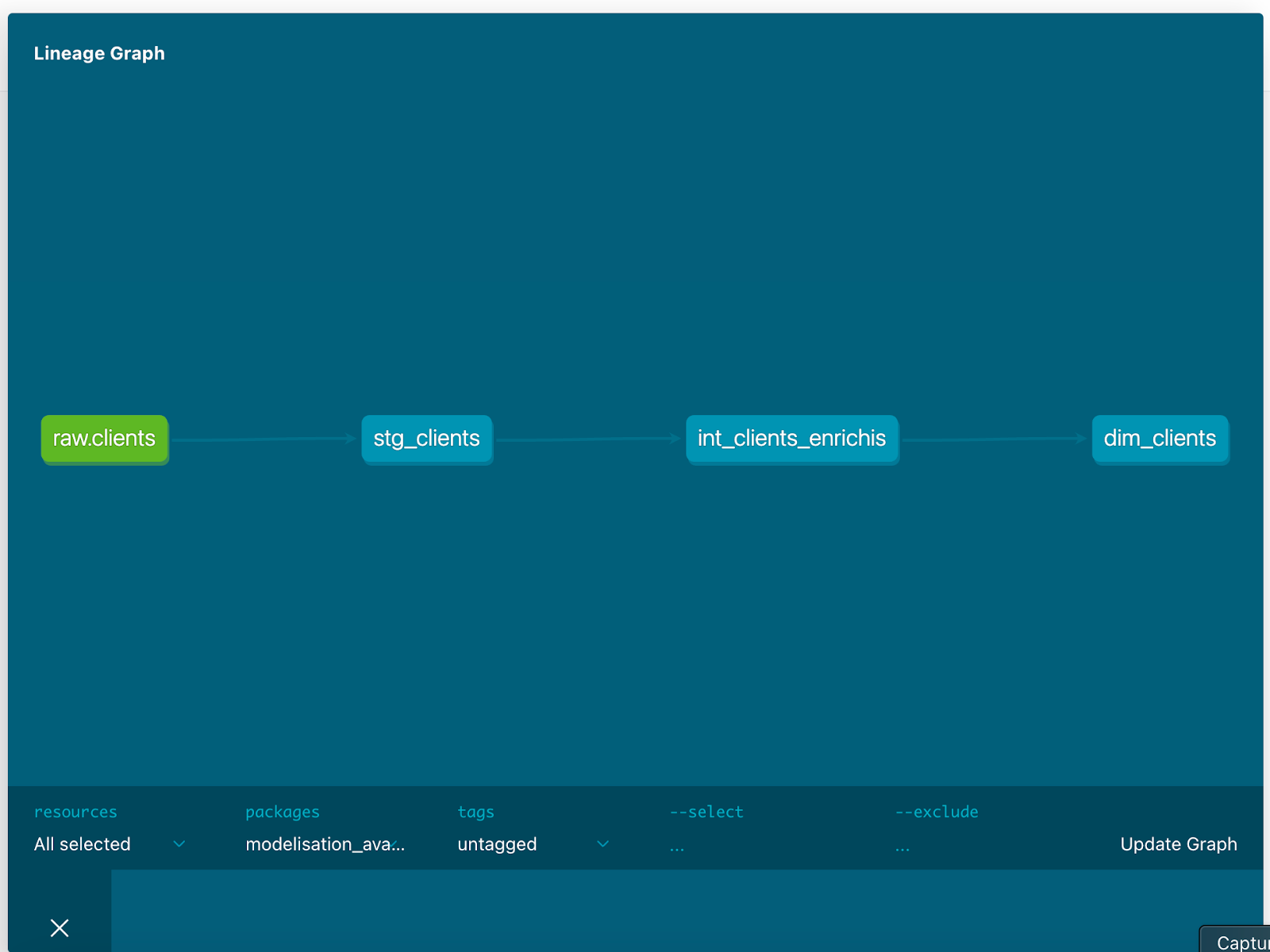
En cliquant sur un modèle, tu peux voir :
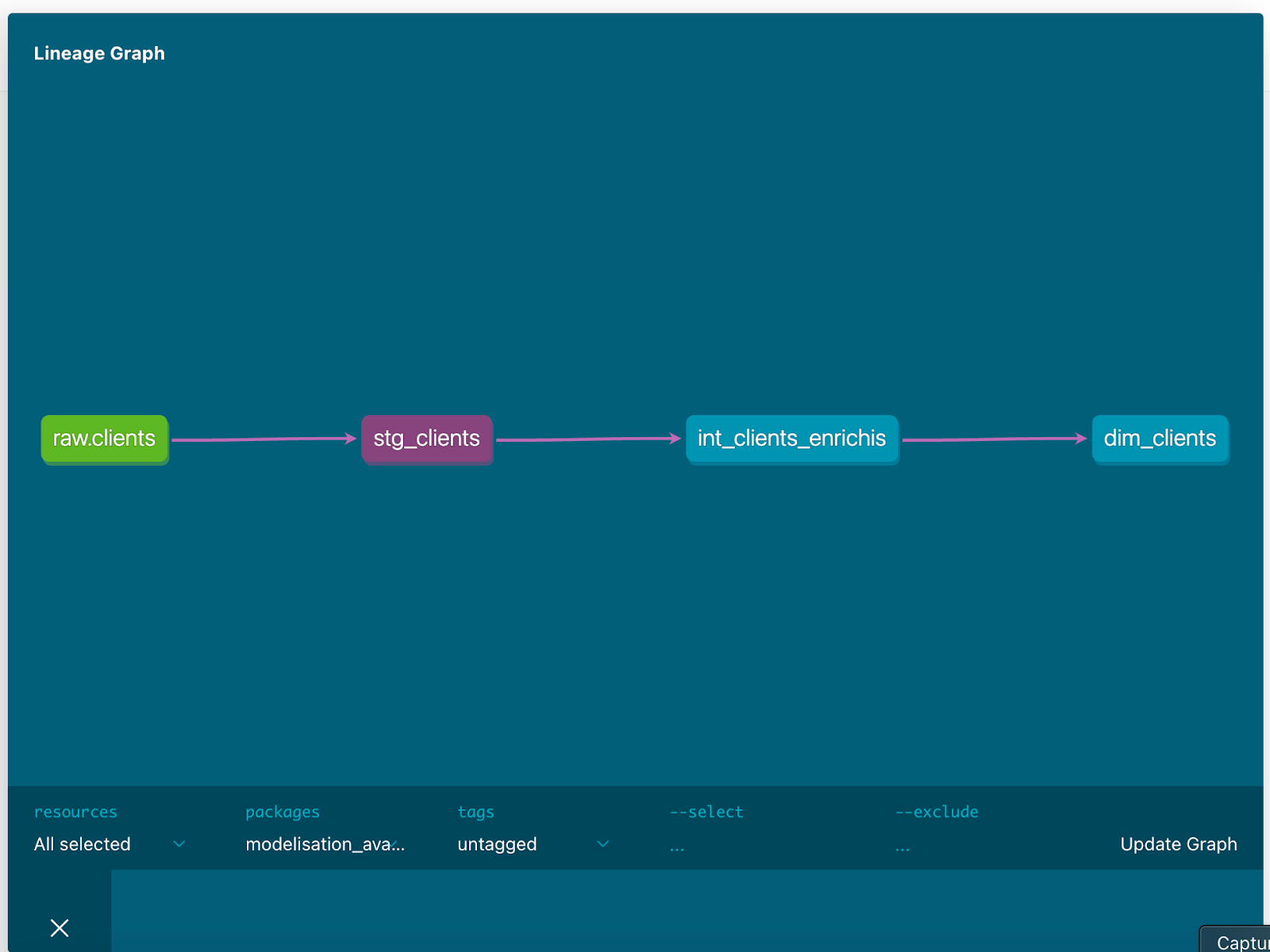
Adopter des conventions de nommage claires, comme préfixer les modèles avec stg_, int_, ou fct_, permet de comprendre rapidement le rôle de chaque modèle. Cela facilite également la navigation dans le projet et la collaboration entre les membres de l'équipe.
DBT utilise le moteur de templating Jinja, permettant de créer des macros pour réutiliser des blocs de code SQL.
Par exemple, une macro peut être utilisée pour gérer les timestamps ou les valeurs nulles de manière cohérente à travers les modèles.
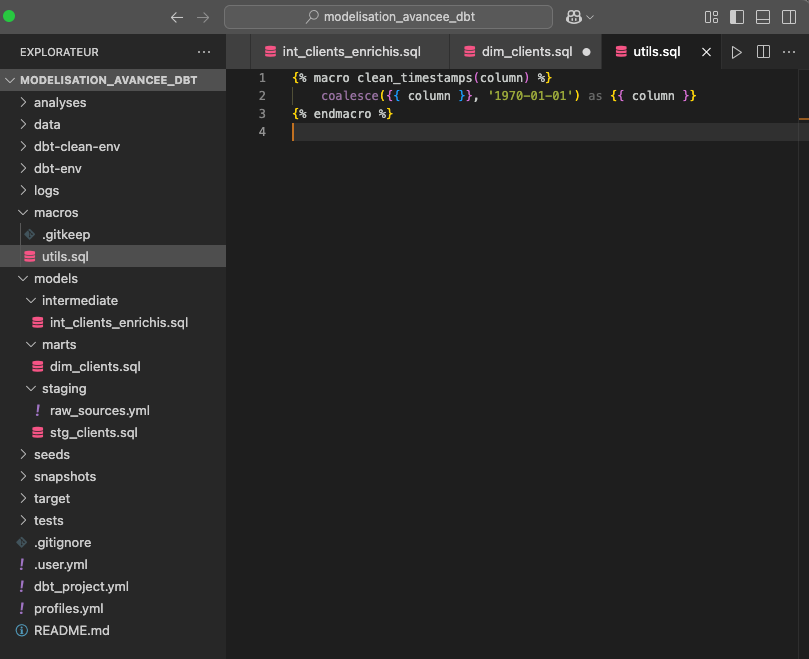
Pour cela, créez un fichier 'utils.sql' dans le dossier 'macros' de votre projet dbt.
Ajoutez-y ce code :
{% macro clean_timestamps(column) %}
coalesce({{ column }}, '1970-01-01') as {{ column }}
{% endmacro %}
Elle permet de nettoyer les colonnes de type timestamp ou date, en remplaçant les NULL par une date par défaut (1970-01-01), de manière réutilisable. Plutôt que de répéter coalesce() à la main dans tous les modèles, vous appellez une seule fois la macro.
Vous pouvez maintenant utiliser cette macro dans n’importe quel modèle, par exemple dans stg_clients.sql :
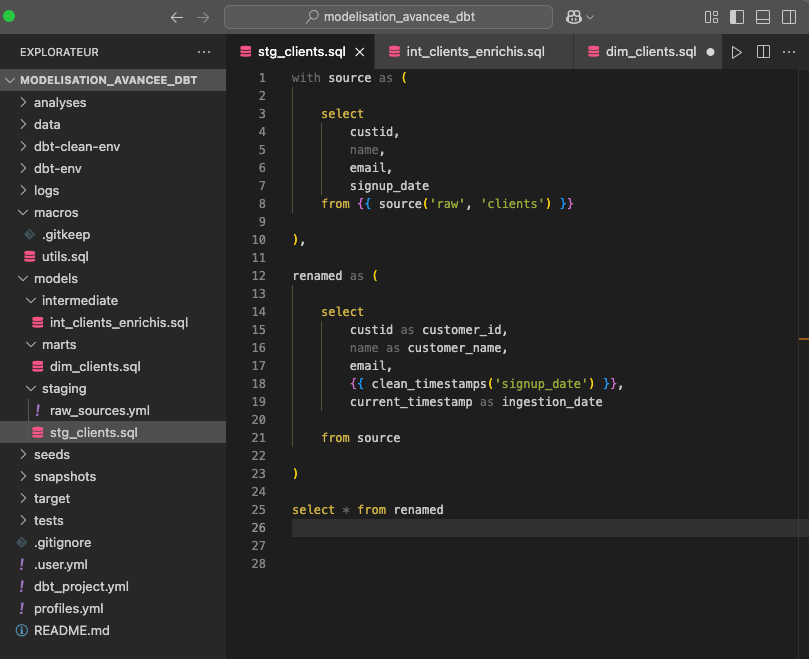
Ici, on utilise {{ clean_timestamps('signup_date') }} pour éviter un coalesce(signup_date, '1970-01-01') manuel.
Cela permet d’avoir un code plus lisible, plus maintenable, surtout quand cette logique est répétée dans plusieurs modèles.
{{formation-dbt="/brouillon"}}
DBT permet d'intégrer des tests directement dans les modèles pour vérifier la qualité des données, comme l'unicité ou la non-nullité des champs.
De plus, la documentation peut être générée automatiquement, incluant des descriptions, des dépendances et des tests, offrant une vue complète du pipeline de données.
Prenons l'exemple d'un pipeline initialement conçu avec un seul modèle fct_commandes traitant la logique de jointure entre clients, produits et paiements. Cette approche peut devenir difficile à maintenir et à comprendre.
En adoptant une modélisation avancée :
Cette refonte améliore la lisibilité, la scalabilité et réduit les erreurs.
Les modèles incrémentaux permettent de traiter uniquement les nouvelles données, améliorant ainsi les performances.
En utilisant la fonction is_incremental(), DBT peut insérer ou mettre à jour des lignes dans une table existante.
Pour notre exemple, imaginons que tu dois charger chaque jour des commandes (orders) dans une table volumineuse. Recalculer la table entière à chaque dbt run serait coûteux et lent.
Avec DBT, tu peux déclarer ton modèle comme incrémental, ce qui permet d’insérer uniquement les nouvelles lignes ou de mettre à jour les lignes modifiées.
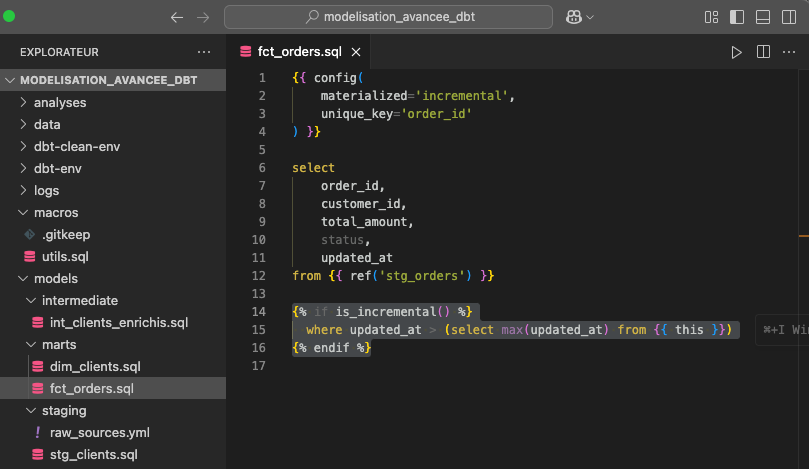
Les snapshots permettent de suivre l'évolution des données dans le temps, utile pour des données évolutives comme les fiches clients. Ils capturent l'état des données à différents moments, facilitant les analyses historiques.
Pour notre exemple, tu veux suivre les changements dans les données clients : quand un email change, quand le statut d’un client évolue, etc.
Les snapshots permettent de stocker des "photos" des données à différents moments, en enregistrant les différences entre les versions.
Il suffit d'ajouter un fichier dans le dossier 'Snapshots' déjà existant :
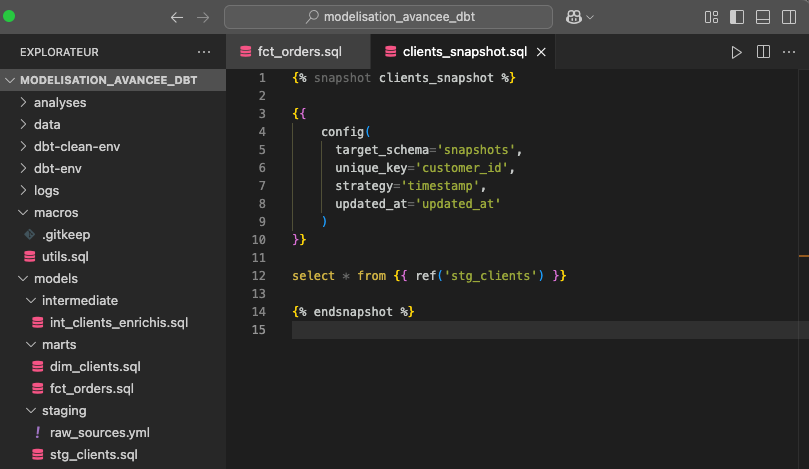
Ce snapshot enregistre une ligne à chaque fois que updated_at change, ce qui permet d’historiser les données client.
Les exposures sont une fonctionnalité puissante mais souvent sous-utilisée.
Elles permettent de documenter les liens entre les modèles DBT et les outils qui les utilisent (comme Looker, Power BI, Tableau…).
Pour notre exemple, imaginons que le dashboard Power BI “Clients actifs par pays” consomme la table dim_clients.
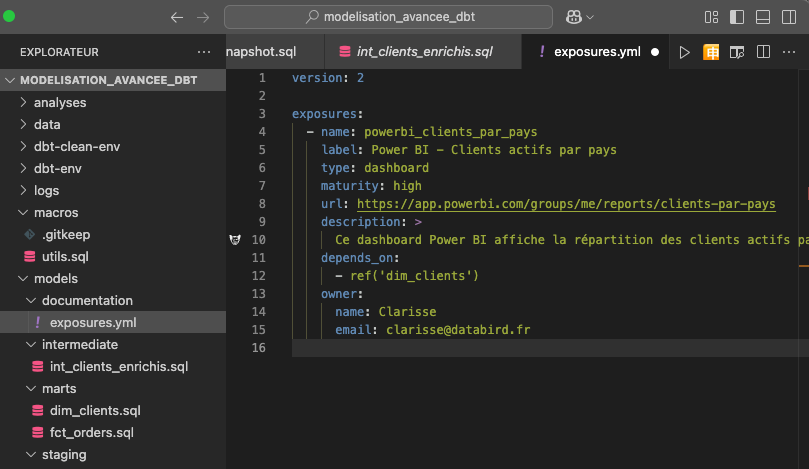
Grâce aux exposures, nous établissons un lien clair entre les modèles DBT et les visualisations BI, ce qui facilite la traçabilité, la gouvernance et l’analyse d’impact.
Lorsque la modélisation avancée DBT est bien mise en place, elle ne repose pas uniquement sur l’organisation en couches.
Elle s’appuie aussi sur des pratiques inspirées du développement logiciel, qui permettent d’améliorer la qualité des données, de fiabiliser le pipeline de transformation et de garantir la pérennité du projet DBT à long terme.
Pour notre exemple, si dim_clients doit garantir l’unicité du customer_id et la présence obligatoire de l’email, il est essentiel de le formaliser via des tests dans DBT.
Ces tests, simples à configurer, permettent de détecter automatiquement toute anomalie dès l’exécution du pipeline.
Pour notre exemple, voici un test pour le modèle dim_clients.sql, à ajouter dans un fichier du même dossier au format .yml :
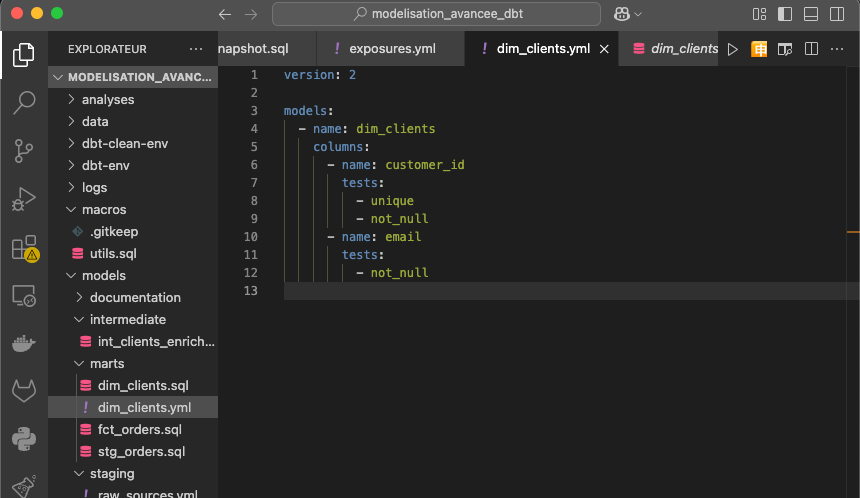
Il suffira ensuite de lancer la commande dbt test dans la console.
Ces règles améliorent la fiabilité du processus de transformation de données, et évitent que des données brutes incorrectes ne polluent vos modèles de données exposés à la BI.
Un projet DBT bien documenté est un projet partageable. Grâce au data build tool DBT, chaque modèle, chaque colonne, chaque couche peut recevoir une description fonctionnelle.
La documentation générée automatiquement offre une vue d’ensemble précieuse, aussi bien pour les data analysts que pour les développeurs SQL ou les métiers.
Vous pouvez également ajouter le code pour la documentation dans un fichier du même dossier que le modèle que vous souhaitez documenter :
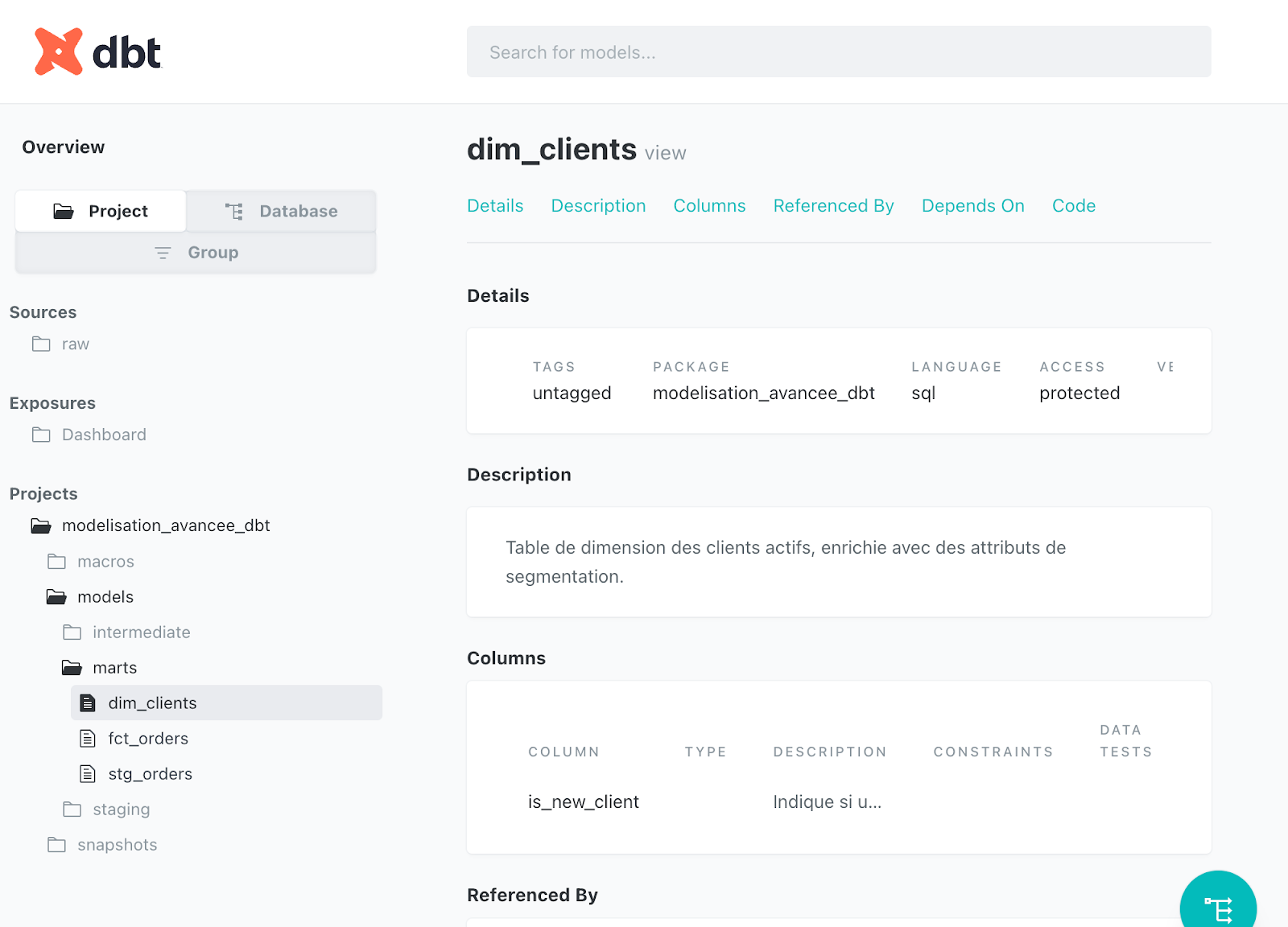
En allant dans dbt docs, nous voyons bien le titre dans 'Description', et la description de la colonne 'is_new_client':
La mise en œuvre d’un projet DBT en entreprise nécessite un contrôle de version rigoureux, notamment avec Git. Chaque mise à jour du pipeline – ajout de colonne, nouvelle transformation – est trackée via des branches, des commits et des pull requests, avec revue de code.
Pour notre exemple, une modification de la logique métier dans int_clients_enrichis peut être déployée de manière sécurisée après validation des tests, puis intégrée au pipeline de production.
Avant de modifier le modèle, créez une branche :
git checkout -b feature/ajout-flag-is_new_client
Cela vous isolera du code en production, et permet de tester sans risque.
Ensuite, faites les modifications dans le modèle (ici dans int_clients_enrichis), et quand tout est OK, validez localement avec dbt grâce à ces commandes :
dbt compile
dbt run --select int_clients_enrichis
dbt test --select int_clients_enrichis
Puis finissez avec un commmit structuré:
git add models/intermediate/int_clients_enrichis.sql
git add models/intermediate/int_clients_enrichis.yml
git commit -m "Ajout de la colonne is_new_client (flag sur 30j) dans int_clients_enrichis"
Une fois relu et approuvé par votre équipe, vous pourrez merger la branche dans main → la modification est intégrée proprement au pipeline DBT.
Ce fonctionnement s’inscrit dans une démarche DevOps appliquée à la data, avec un déploiement contrôlé des modèles SQL.
Chez DataBird, nous proposons une formation avancée sur DBT, afin de maîtriser la modélisation avancée, l'automatisation des tests, la documentation et l'optimisation des pipelines de données. Cette formation inclut des projets pratiques, un coaching par des experts et un support personnalisé.
{{formation-dbt="/brouillon"}}



