

Mis à jour le
19/3/2026
Découvrez l'optimisation des requêtes SQL avec EXPLAIN et les indexes. Évitez les pièges de performance et améliorez l'efficacité de vos bases de données.
En bref : L'optimisation de requête SQL via la commande EXPLAIN est une compétence vitale pour éviter la lenteur des dashboards. EXPLAIN permet de visualiser le plan d'exécution d'un SGBD, identifiant les "Sequential Scans" coûteux. En couplant cet outil avec EXPLAIN ANALYZE et une stratégie d'indexation ciblée, un Data Analyst peut diviser par 10 le temps de réponse de ses requêtes sur des volumes massifs (Big Data).
Optimiser une requête SQL, ce n’est pas une option : c’est une nécessité, dès que votre base de données grossit ou que votre application web monte en charge.
L'outil EXPLAIN (et sa version avancée EXPLAIN ANALYZE) est votre meilleur allié pour observer le plan d'exécution d'une requête SQL. Il vous montre en détail comment le système de gestion de base de données (SGBD) lit vos tables, applique vos conditions et combine les résultats.
L'objectif ? Trouver les goulets d’étranglement dans vos requêtes SQL et améliorer leurs performances.
Tout au long de cet article, nous utiliserons comme exemple une base e-commerce avec plusieurs tables :
On cherche à optimiser une requête SQL qui retourne les produits les plus vendus en mars 2025.
Quand vous exécutez une instruction comme SELECT ... FROM ..., la base de données ne va pas simplement "suivre" vos lignes de code. Elle passe par un composant appelé planificateur, qui construit un plan d'exécution. Ce plan est une série d’opérations internes, que le système va exécuter étape par étape : lectures de tables, jointures, tris, regroupements…
L’objectif d’EXPLAIN est de révéler ce plan, afin que vous puissiez observer ce que fait réellement la base de données, et pas seulement ce que vous lui demandez de faire en SQL.
Voici la requête SQL brute que nous cherchons à améliorer :
Quand nous exécutons cette requête, nous souhaitons savoir :
Pour cela, nous allons utiliser EXPLAIN.
Pour obtenir le plan d'exécution, il suffit d'ajouter EXPLAIN devant la requête :
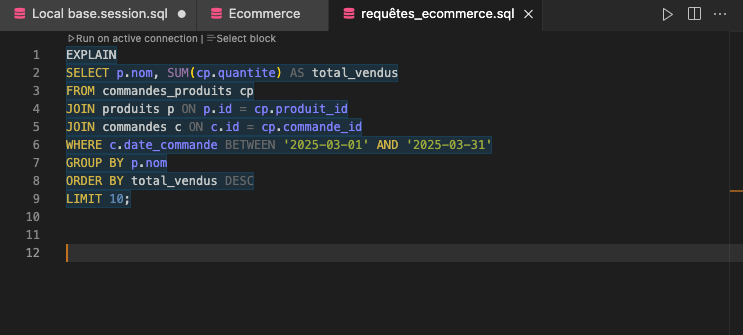
Le moteur SQL va alors nous afficher le plan prévu, sans exécuter réellement la requête.
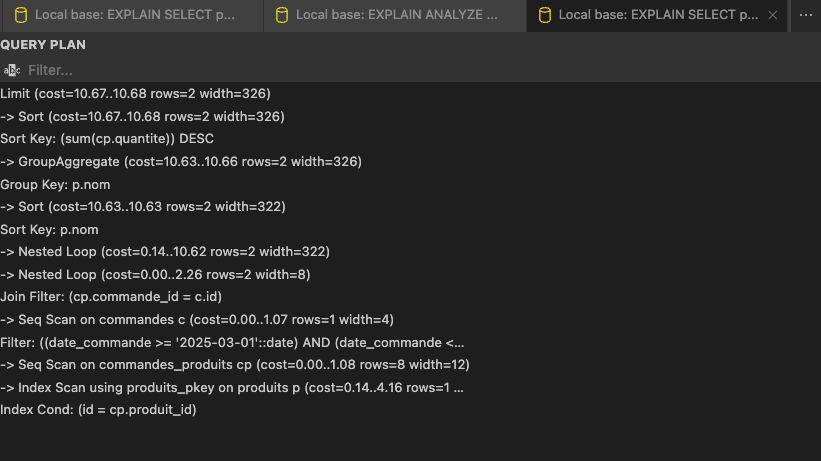
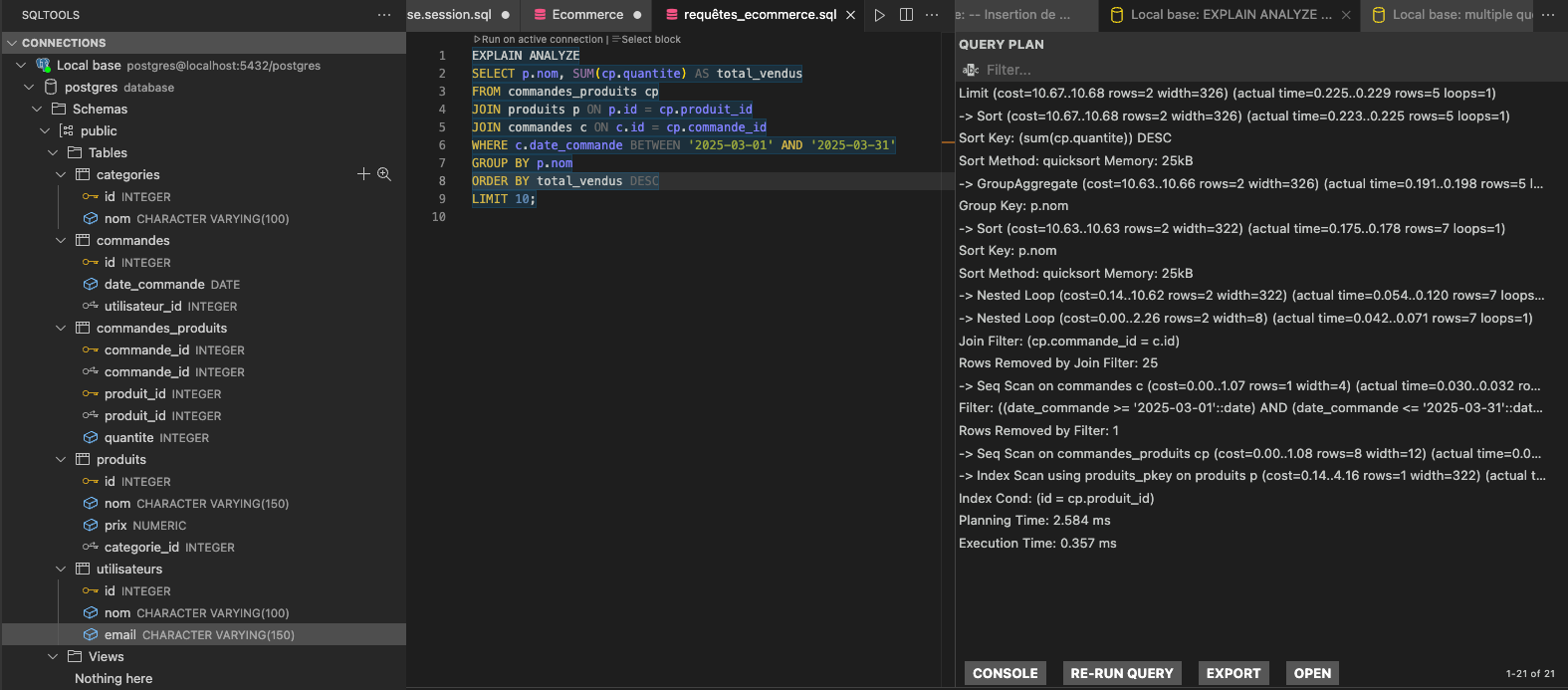
En analysant le plan affiché dans SQLTools, nous voyons que PostgreSQL commence par appliquer la clause LIMIT 10. Cela est visible avec la ligne Limit (cost=10.67..10.68 rows=2 width=326). Avant d’appliquer cette limite, la base trie les résultats en utilisant la somme des quantités commandées, conformément à l’ordre demandé par ORDER BY SUM(cp.quantite) DESC.
Cette étape de tri est indiquée juste en dessous avec Sort (cost=10.67..10.68 rows=2 width=326), où le tri est effectué sur sum(cp.quantite).
Le coût associé à cette opération est très faible, car notre base contient peu de données et seulement deux lignes sont triées. Juste après, PostgreSQL procède à une agrégation des résultats avec la commande GroupAggregate (cost=10.63..10.66 rows=2 width=326), en regroupant les lignes selon le nom du produit (Group Key: p.nom). C'est cette étape qui permet de calculer la quantité totale vendue pour chaque produit.
Avant d’agréger, PostgreSQL trie d'abord les lignes par p.nom, ce qui est indispensable pour permettre une agrégation efficace. Cela se traduit par une étape Sort (cost=10.63..10.63 rows=2 width=322), qui trie les produits sur leur nom.
En descendant plus bas dans le plan, nous voyons deux niveaux de Nested Loop. Cela signifie que PostgreSQL utilise des boucles imbriquées pour joindre successivement les tables commandes_produits, commandes et produits.
Le premier Nested Loop assemble commandes_produits avec commandes en reliant les commandes aux produits commandés. Le second Nested Loop combine ensuite ce résultat avec les informations sur les produits eux-mêmes.
Pour accéder aux données de la table commandes, PostgreSQL utilise un Seq Scan comme l'indique Seq Scan on commandes c. Cela signifie que l’ensemble des lignes de la table est parcouru pour appliquer le filtre sur la date, défini dans la clause WHERE c.date_commande BETWEEN '2025-03-01' AND '2025-03-31'. Ce fonctionnement est acceptable pour une table de petite taille, mais il pourrait rapidement devenir un goulot d’étranglement si la base grossissait fortement.
La table commandes_produits est également parcourue entièrement, avec un Seq Scan on commandes_produits cp.
Enfin, l’accès à la table produits est optimisé grâce à un Index Scan using produits_pkey on produits p. Ici, PostgreSQL utilise l'index primaire sur produits pour retrouver les informations sur chaque produit de manière rapide et efficace.
Même si la requête est fonctionnelle, elle n'est pas encore optimisée. La présence d’un Seq Scan sur commandes est un signal d’alerte, car sur une table de plusieurs millions de lignes, cette stratégie de lecture deviendrait extrêmement coûteuse en ressources et ralentirait considérablement l'exécution.
Si EXPLAIN montre uniquement le plan théorique de la requête, EXPLAIN ANALYZE va plus loin en exécutant réellement la requête et en mesurant ce qu’il se passe en pratique.
Cette commande nous donne des informations cruciales : le temps d'exécution réel, noté Execution Time, le nombre de lignes réellement parcourues à chaque étape, appelé actual rows, et la différence entre les estimations prévues et la réalité constatée. C'est cet écart qui nous permet d’identifier avec précision les opérations coûteuses dans une requête SQL.
Pour tester cela sur notre exemple e-commerce, nous exécutons la commande suivante :
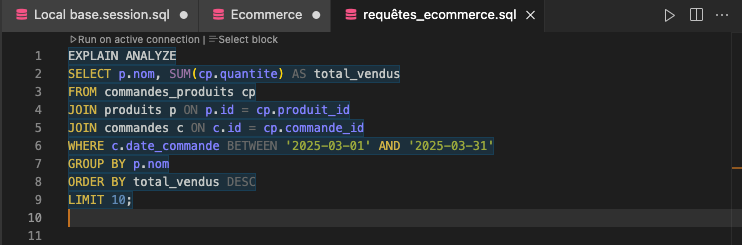
Le plan obtenu montre que la Planning Time reste rapide, car la requête est relativement simple. Le Execution Time est également faible pour l’instant, car notre base contient encore peu de données.
Toutefois, nous remarquons que le moteur PostgreSQL effectue un balayage complet de la table commandes pour filtrer sur la période de mars 2025, ce qui pourrait devenir problématique à plus grande échelle.
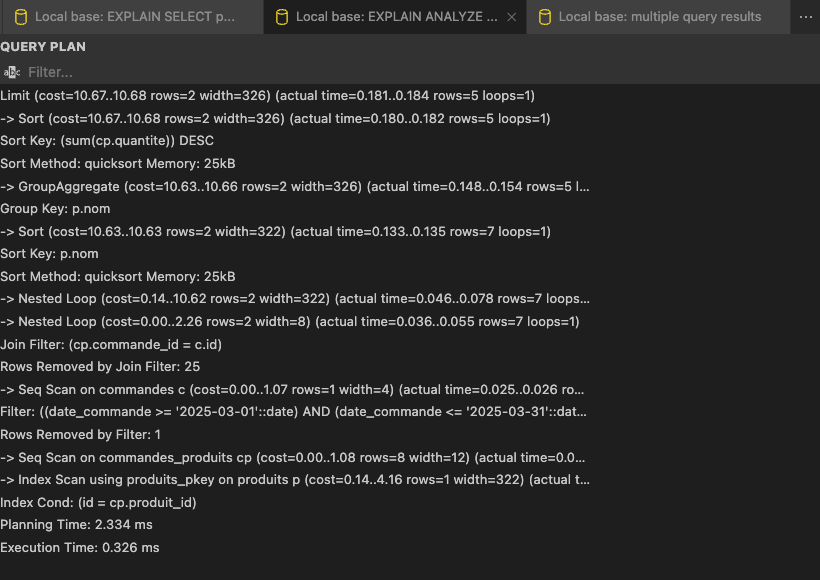
En lisant attentivement ce plan d'exécution, plusieurs pistes d'optimisation apparaissent. Il serait judicieux de supprimer le Seq Scan sur la table commandes, en facilitant l'accès direct aux lignes concernées par notre filtre de date. De même, nous pourrions chercher à accélérer l’étape de tri sur SUM(cp.quantite), nécessaire pour établir l'ordre des produits les plus vendus.
Puisque notre requête filtre les résultats en fonction de la colonne date_commande, la solution naturelle consiste à créer un index sur cette colonne. Cela permettra à PostgreSQL d’utiliser un Index Scan plutôt que de parcourir toute la table.
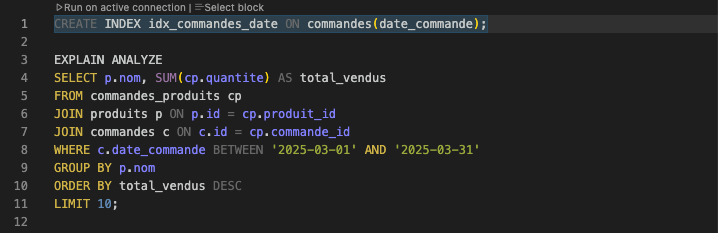
Voici la commande CREATE INDEX correspondante :
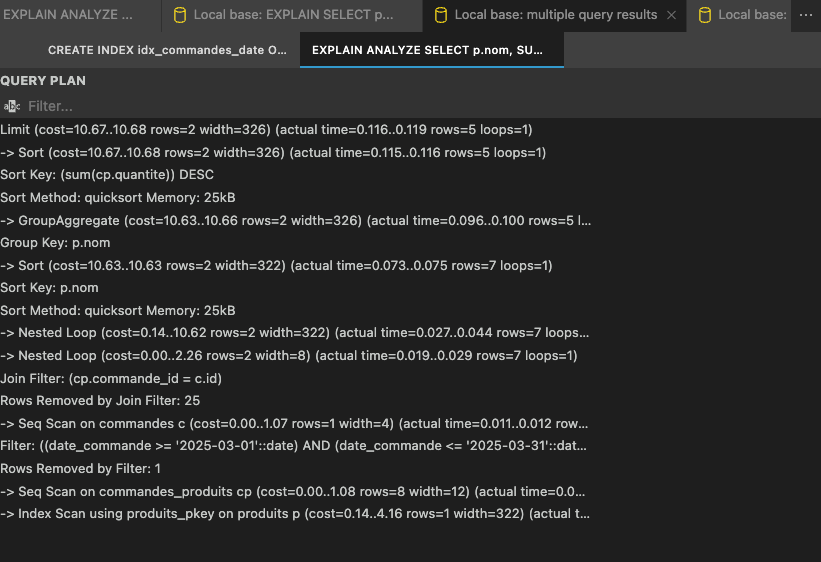
L’index sur date_commande avait pour but de remplacer le scan séquentiel par un accès rapide, mais dans notre cas, PostgreSQL continue à parcourir toute la table car le volume de données est encore trop faible pour que l'utilisation de l'index soit considérée comme rentable.
Jusqu’à présent, notre base de données contient très peu d’entrées. Les plans d’exécution que nous analysons restent donc simples et les temps d’exécution sont extrêmement faibles. Mais que se passerait-il si notre base grossissait vraiment, comme dans un vrai projet e-commerce ?
Un site de vente en ligne traite souvent plusieurs centaines de milliers de commandes, voire des millions d’achats, chaque année. Dans ces conditions, les plans d’exécution que nous observons seraient totalement différents, et certaines opérations, aujourd’hui insignifiantes, deviendraient de véritables goulets d’étranglement.
Voyons maintenant comment anticiper ce changement de volume et optimiser notre requête SQL pour qu’elle reste performante même sur une très grande base.
Quand une base contient seulement quelques lignes, PostgreSQL peut se permettre de lire toute une table sans que cela n’ait un impact significatif sur le temps d’exécution. C’est pour cela que dans nos premiers tests, malgré la création de l’index sur date_commande, PostgreSQL continuait à utiliser un Seq Scan.
Mais avec des tables contenant des millions de lignes, un Seq Scan devient extrêmement coûteux : il implique de parcourir l’ensemble des données, même si seules quelques lignes correspondent aux critères de filtrage.
À partir d’un certain seuil, PostgreSQL adapte son comportement : il privilégiera l’utilisation d’un Index Scan dès qu’il détectera qu’un index permet d’accéder à beaucoup moins de lignes que la table complète.
Nous utilisons la même requête que précédemment, cette fois précédée de EXPLAIN ANALYZE :
Dans le plan d’exécution obtenu sur notre base massive, plusieurs éléments clés prouvent que l’optimisation a fonctionné : PostgreSQL utilise bien l’index idx_commandes_date via un Bitmap Index Scan, ce qui lui permet de filtrer efficacement les commandes du mois ciblé sans parcourir toute la table.
La jointure entre commandes et commandes_produits se fait via un Hash Join, bien plus adapté qu’un Nested Loop sur des millions de lignes.
L’agrégation par produit, le tri sur la somme des quantités, puis l’application du LIMIT sont exécutés dans un ordre logique et performant.
Enfin, le temps total d’exécution reste sous la seconde, preuve que malgré la taille de la base, l’optimisation structurelle (index + schéma bien pensé) permet à PostgreSQL de répondre efficacement sans s'effondrer sous la charge.
Quand une base est petite, tout semble rapide.
Mais dès que le volume de données explose, chaque ligne inutilement lue, chaque jointure mal optimisée, chaque index manquant devient un coût caché pour votre application.
C’est là que EXPLAIN ANALYZE entre en jeu : il vous permet d’observer, de comprendre, puis d’optimiser précisément là où c’est nécessaire. Et cette compétence, elle fait la différence entre une application rapide et une base qui rame en production.
Chez DataBird, on ne se contente pas de vous montrer la syntaxe SQL.
On vous apprend à penser comme un moteur de base de données, à lire un plan d’exécution, à construire des requêtes performantes, que vous soyez sur PostgreSQL, MySQL ou un autre SGBD.
Nos formations SQL vont bien au-delà du SELECT * FROM.
Si vous travaillez avec des bases en production ou que vous visez un rôle en data (Data Analyst, Data Engineer, Dev Back-End…), notre formation SQL avancé & optimisation est faite pour vous.
{{formation-sql="/brouillon"}}



