

Mis à jour le
19/3/2026
Découvrez les meilleures pratiques pour un SQL maintenable en équipe. Apprenez les conventions de nommage, les commentaires et améliorez vos collaborations

En bref : Pour qu'un projet Data passe à l'échelle, le SQL doit être traité comme du code applicatif. Cet article détaille les 3 piliers d'un SQL maintenable en équipe : l'adoption d'une charte de nommage rigoureuse, une structure de requête standardisée et l'utilisation d'outils d'automatisation comme dbt ou SQLFluff. L'objectif ? Réduire la dette technique et faciliter la collaboration entre Data Analysts et Analytics Engineers.
Dans toutes les équipes techniques qui manipulent des bases de données, il arrive un moment où le SQL devient un casse-tête collectif.
Entre les requêtes jetées rapidement en production, les noms de colonnes obscurs et les absences de commentaire, maintenir le code devient une charge invisible… jusqu’au jour où une mise à jour casse tout.
Cet article vous proposera une méthode claire pour écrire du SQL maintenable en équipe. Nous parlerons bonnes pratiques, structure du code, nommage cohérent, commentaires utiles, et surtout collaboration. Et nous illustrons tout ça avec un projet fil rouge : l’analyse des ventes dans une base e-commerce!
Quand on pense développement, on pense souvent à Python ou JavaScript. Pourtant, en entreprise, le SQL est au cœur de nombreux systèmes.
Qu'on travaille avec SQL Server, PL SQL, ou des outils comme Snowflake, la qualité du SQL détermine la fiabilité des données en aval.
Mais voilà : ce langage, pourtant structuré, est souvent écrit « à la volée », sans normes. Résultat : une lecture difficile, des erreurs fréquentes lors des mises à jour, et une absence totale de réutilisation.
Voici un exemple réel d’un code non maintenable :
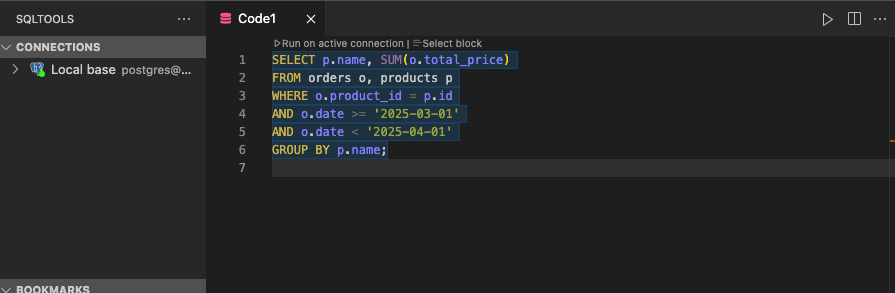
Ce genre de requête, sans indentation, sans alias clair, sans commentaire, devient vite un cauchemar collectif.
Pour une équipe, la première étape consiste à définir une charte de codage SQL. Cela concerne à la fois la structure du code, le style, mais aussi la gestion des procédures ou des fonctions.
Voici notre requête précédente réécrite selon des conventions simples :
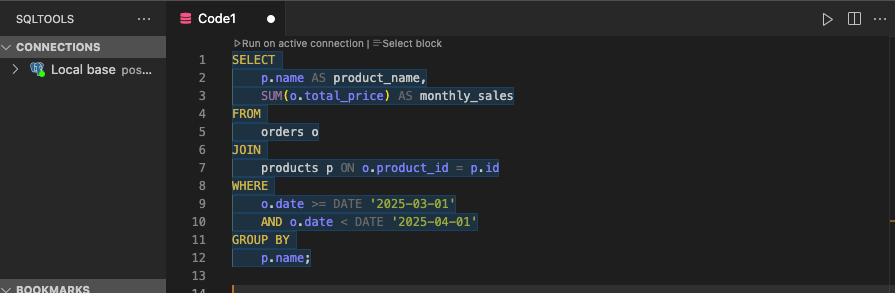
La lisibilité est améliorée, la structure est claire, et la logique métier ressort immédiatement. C’est la base pour toute collaboration.

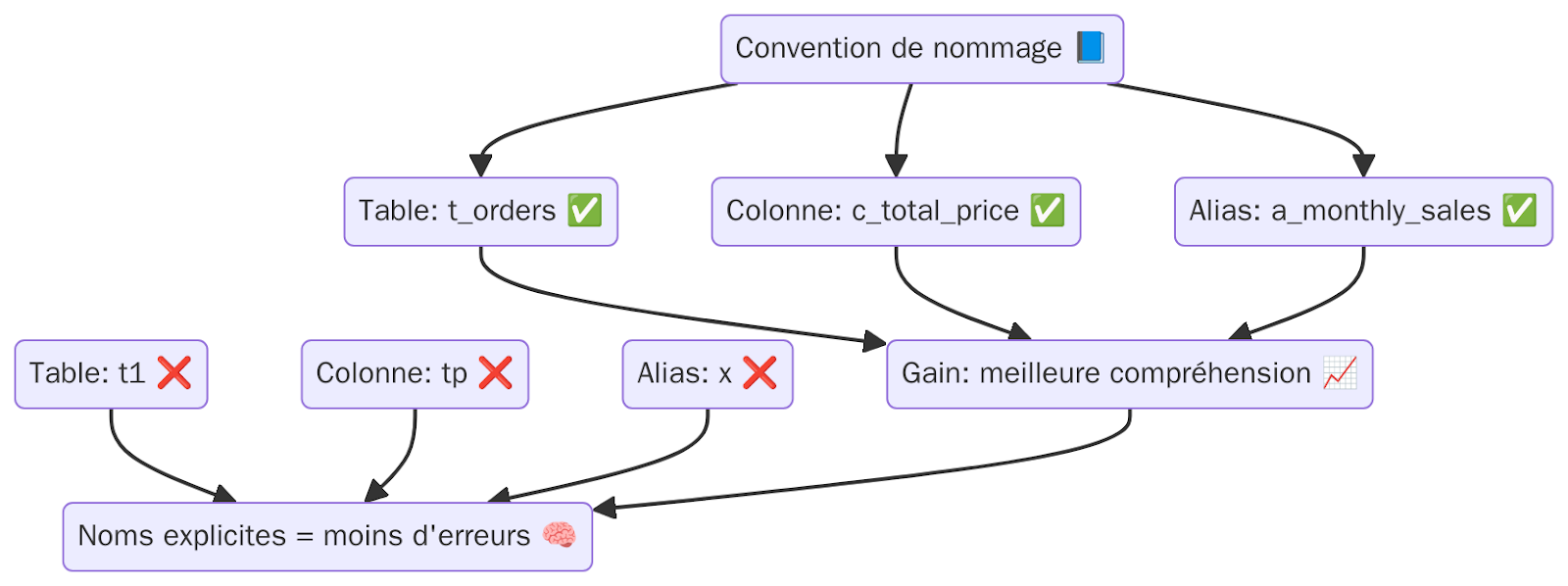
Dans une base de données bien structurée, les noms doivent être auto-explicites. Une équipe qui partage des noms clairs gagne un temps considérable en lecture et en correction.
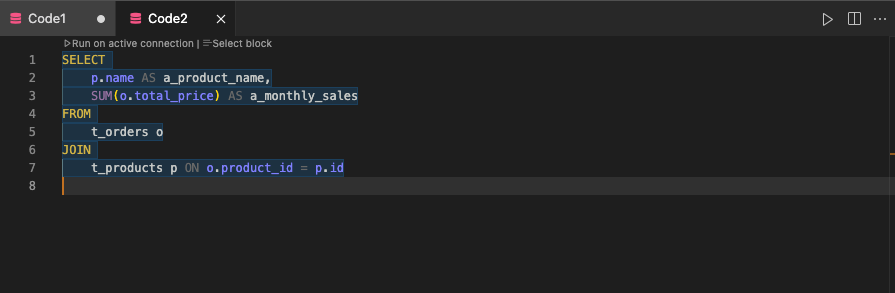
Reprenons notre exemple : remplacer tp par total_price, ou t1 par orders, rend la compréhension immédiate.
Vous pouvez adopter une convention simple pour vos projets :
Cela permet de distinguer immédiatement chaque élément de la requête.
Un bon commentaire ne décrit pas ce que fait le code. Il explique pourquoi on le fait.
Cette nuance change tout. Quand vous écrivez du SQL, vous savez ce que vous faites. Mais la personne qui relira votre requête dans trois mois n’aura peut-être aucun contexte.
Pire : si vous changez de poste ou quittez le projet, c’est votre commentaire qui devient la seule source de compréhension.
Prenons un exemple de notre projet e-commerce. Voici une requête avec un commentaire utile :
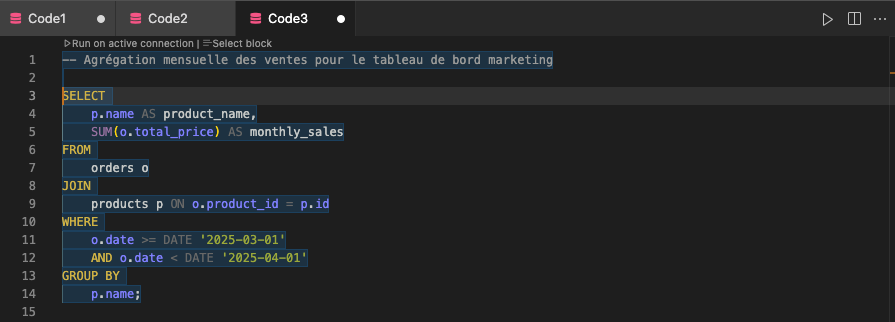
Ici, le commentaire donne immédiatement la finalité métier de la requête. Ce genre d’explication simple évite des allers-retours inutiles lors des mises à jour ou de l’intégration à un tableau de bord.
Voici quelques règles simples et efficaces à appliquer pour améliorer la lisibilité et la maintenance de vos requêtes SQL :
Chaque requête SQL exécute une ou plusieurs tâches métier. Il est essentiel de documenter ce que chaque bloc représente : agrégation, jointure, filtrage métier, transformation.
-- Filtrage des commandes passées dans le cadre d'une opération spéciale
WHERE o.promo_code = 'SPRING2025'
Lorsqu’un filtre repose sur une logique spécifique à un événement, une période ou une règle métier peu évidente, notez-le clairement. Cela évite que quelqu’un le supprime en pensant qu’il est inutile.
-- On exclut les commandes annulées avant expédition
AND o.status != 'cancelled_before_shipping'
Pas besoin de surcharger le SQL avec des lignes du type
-- sélectionne les produits.
Cela gêne plus qu’autre chose.
Dans des environnements comme SQL Server ou PL SQL, vous travaillez parfois avec des procédures complexes, des packages, ou des scripts longue durée.
Dans ces cas-là, documentez les entrées, les sorties, les exceptions possibles, et ajoutez un en-tête descriptif :
-- Procédure : calc_monthly_revenue
-- But : Calcule le chiffre d'affaires mensuel par catégorie produit
-- Entrée : start_date DATE, end_date DATE
-- Sortie : Table temporaire avec catégorie et CA
Même si le SQL n’est pas un langage objet, il fait partie intégrante de votre pipeline de développement.
Le négliger serait une erreur stratégique, surtout en équipe. Traiter vos requêtes comme des scripts “jetables” empêche toute forme de suivi, de maintenance, ou de collaboration sérieuse.
Créez un répertoire /sql dans vos projets et versionnez vos fichiers .sql dans Git, comme vous le faites pour du code Python ou Java.
Vous pourrez ainsi suivre les évolutions des requêtes, commenter et reviewer les modifications via pull request et même gérer les mises à jour de vos bases de données proprement.
Une requête SQL ne devrait jamais être poussée directement en production sans test ni validation.
Voici un petit processus que nous vous proposons, simple mais efficace :
Travailler à plusieurs sur des requêtes SQL sans règles ni outils, c’est comme coder en Java sans IDE.
Heureusement, plusieurs solutions facilitent aujourd’hui la lecture, l’automatisation, la documentation, et les tests.
Un linter (outil qui analysant le code automatiquement) et formateur SQL compatible avec SQL Server, Snowflake, PostgreSQL, etc. Il applique automatiquement vos règles de style, alerte sur les mauvaises pratiques et formate votre code.
Parfait pour structurer vos projets SQL avec des modèles réutilisables, des tests automatisés et de la documentation générée automatiquement. Nous avons plusieurs articles sur notre Blog Databird expliquant l'utilisation de DBT Cloud.
Des IDEs SQL puissants qui améliorent la lecture, la navigation, la création de requêtes complexes, et même l’intégration avec Git.
Nous vous avons concocté un comparatif des différents outils :

Chez DataBird, notre formation SQL avancé est pensée pour les professionnels qui travaillent en équipe sur des bases de données critiques. C’est la suite logique pour toute équipe qui veut monter en compétence et industrialiser son usage de SQL, que ce soit sur SQL Server, PL SQL, ou des environnements cloud comme Snowflake.
{{formation-sql="/brouillon"}}


